[init]
This commit is contained in:
commit
353c4f7f86
|
|
@ -0,0 +1,96 @@
|
|||
# Noise2Same
|
||||
Official TensorFlow implementation for the [paper](https://arxiv.org/abs/2010.11971) presented on NeurIPS 2020 titled
|
||||
"*Noise2Same: Optimizing A Self-Supervised Bound for Image Denoising*".
|
||||
|
||||
<img src="./figures/cover.jpg" width="80%">
|
||||
<img src="./figures/visual.jpg" width="80%">
|
||||
|
||||
## Environment Requirements
|
||||
- jupyter
|
||||
- python == 3.7.2
|
||||
- tensorflow >=1.10 & <=1.15
|
||||
- scipy
|
||||
- skimage
|
||||
- tifffile
|
||||
|
||||
## Usage
|
||||
|
||||
### To reproduce our results
|
||||
|
||||
#### Dataset and model checkpoint download
|
||||
We uploaded the datasets used in our experiments and the model checkpoint files to the google drive [here](https://drive.google.com/drive/folders/1VYMo1OoaGxoOLNx6-qIt2Wg03lsZw_kA?usp=sharing). You can download the files and put them in the folders ``Denoising_data`` and ``trained_models``. More details about the dataset construction and the source of data can be found under [Denoising_data](./Denoising_data).
|
||||
|
||||
We have provided four examples in Jupyter Notebook that can reproduce our results in the paper. Once you have downloaded the dataset (and the pretrained chechpoints if you want to skip training), you can simply go through the notebooks for reproduction.
|
||||
|
||||
### To train, evaluate and predict with your own datasets
|
||||
You can follow the examples in Jupyter Notebook for denoising with RGB images, grayscale images and 3D images.
|
||||
|
||||
#### To be specific, the following code is used to build the model.
|
||||
```
|
||||
from models import Noise2Same
|
||||
model = Noise2Same(model_dir, model_name, dimension, in_channels)
|
||||
```
|
||||
where ``model_dir`` and ``model_name`` will specify the path to your checkpoint files, ``dimension`` refers to the dimension of image *(2 or 3)* and ``in_channels`` refers to the number of channels of input images.
|
||||
|
||||
#### The following code is used for **training**.
|
||||
```
|
||||
model.train(X, patch_size, validation=X_val, batch_size, steps)
|
||||
```
|
||||
where ``X`` and ``X_val`` are the noisy images for training/validation of shape ``[n_samples, width, length, n_channels]`` and of type ``float32``, ``patch_size`` specify the size to crop input images to training patches. Note that the input image should be **normalized** before input for training.
|
||||
|
||||
#### The following codes are for **prediction**.
|
||||
|
||||
- For prediction of single image,
|
||||
```
|
||||
model.predict(img[, im_mean, im_std])
|
||||
```
|
||||
where ``img`` is the noisy image for prediction, ``im_mean`` and ``im_std`` are the mean and standard deviation. If ``im_mean`` and ``im_std`` are not specified, it will use ``img.mean()`` and ``img.std()`` by default.
|
||||
|
||||
- For prediction of batched images (and you have enough GPU memory),
|
||||
```
|
||||
model.batch_predict(images.astype('float32'), batch_size[, im_mean, im_std])
|
||||
```
|
||||
|
||||
- For extremely large images, e.g. CARE 3D images,
|
||||
```
|
||||
model.crop_predict(image, crop_size, overlap[, im_mean, im_std])
|
||||
```
|
||||
|
||||
### Use Noise2Same under other frameworks
|
||||
You can follow the pseudocode below to build the Noise2Same model.
|
||||
|
||||
Given the noisy images ``images``, the masked noisy images ``masked_images`` and masking map ``mask`` with masked locations being 1 and other 0,
|
||||
|
||||
```
|
||||
net = YourNetwork()
|
||||
# The two net() below should share their weights
|
||||
out_raw = net(images)
|
||||
out_masked = net(masked_images)
|
||||
|
||||
l_rec = reduce_mean((out_raw - images)^2)
|
||||
l_inv = reduce_sum((out_raw - out_masked)^2 * mask) / reduce_sum(mask)
|
||||
loss = l_rec + 2 * sqrt(l_inv)
|
||||
```
|
||||
|
||||
## Reference
|
||||
```
|
||||
@inproceedings{xie2020noise2same,
|
||||
author = {Xie, Yaochen and Wang, Zhengyang and Ji, Shuiwang},
|
||||
title = {Noise2{S}ame: Optimizing A Self-Supervised Bound for Image Denoising},
|
||||
booktitle = {Advances in Neural Information Processing Systems},
|
||||
pages = {20320--20330},
|
||||
volume = {33},
|
||||
year = {2020}
|
||||
}
|
||||
```
|
||||
|
||||
## Web Demo
|
||||
You can create a web-based demo to run inference by running the `demo.py` file, which uses the `gradio` Python library.
|
||||
|
||||
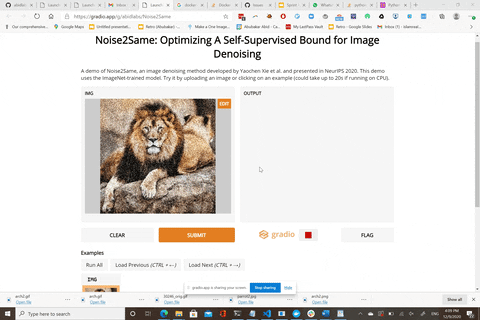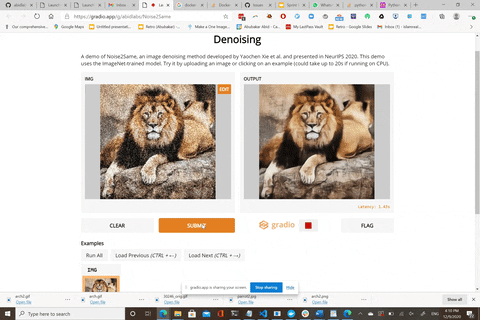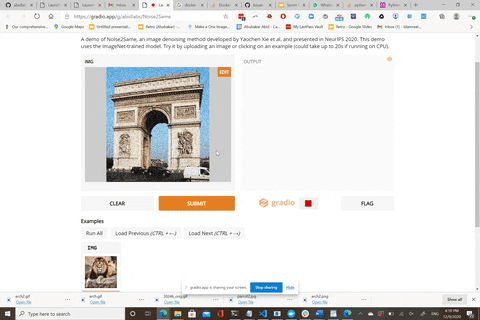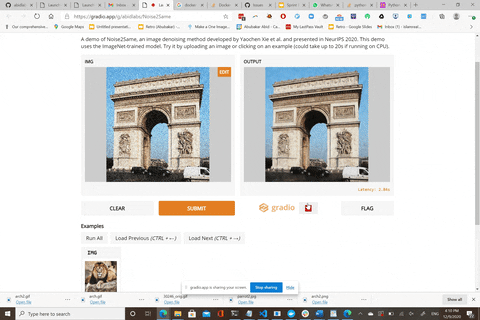
Here is a live demo: https://gradio.app/g/Noise2Same
|
||||
|
||||
The live demo uses the model pre-trained on 20,000 noisy images generated from ImageNet ILSVRC2012 validation dataset.
|
||||
|
||||
|
||||
|
||||
We thank [Abubakar Abid](https://github.com/abidlabs) for building this awesome web demo for us!
|
||||
|
|
@ -0,0 +1,91 @@
|
|||
import logging, os
|
||||
logging.disable(logging.WARNING)
|
||||
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
|
||||
|
||||
import tensorflow as tf
|
||||
from network_configure import conf_basic_ops
|
||||
|
||||
|
||||
"""This script defines basic operaters.
|
||||
"""
|
||||
|
||||
|
||||
def convolution_2D(inputs, filters, kernel_size, strides, use_bias, name=None):
|
||||
"""Performs 2D convolution without activation function.
|
||||
If followed by batch normalization, set use_bias=False.
|
||||
"""
|
||||
return tf.layers.conv2d(
|
||||
inputs=inputs,
|
||||
filters=filters,
|
||||
kernel_size=kernel_size,
|
||||
strides=strides,
|
||||
padding='same',
|
||||
use_bias=use_bias,
|
||||
kernel_initializer=conf_basic_ops['kernel_initializer'],
|
||||
name=name,
|
||||
)
|
||||
|
||||
def convolution_3D(inputs, filters, kernel_size, strides, use_bias, name=None):
|
||||
"""Performs 3D convolution without activation function.
|
||||
If followed by batch normalization, set use_bias=False.
|
||||
"""
|
||||
return tf.layers.conv3d(
|
||||
inputs=inputs,
|
||||
filters=filters,
|
||||
kernel_size=kernel_size,
|
||||
strides=strides,
|
||||
padding='same',
|
||||
use_bias=use_bias,
|
||||
kernel_initializer=conf_basic_ops['kernel_initializer'],
|
||||
name=name,
|
||||
)
|
||||
|
||||
def transposed_convolution_2D(inputs, filters, kernel_size, strides, use_bias, name=None):
|
||||
"""Performs 2D transposed convolution without activation function.
|
||||
If followed by batch normalization, set use_bias=False.
|
||||
"""
|
||||
return tf.layers.conv2d_transpose(
|
||||
inputs=inputs,
|
||||
filters=filters,
|
||||
kernel_size=kernel_size,
|
||||
strides=strides,
|
||||
padding='same',
|
||||
use_bias=use_bias,
|
||||
kernel_initializer=conf_basic_ops['kernel_initializer'],
|
||||
name=name,
|
||||
)
|
||||
|
||||
def transposed_convolution_3D(inputs, filters, kernel_size, strides, use_bias, name=None):
|
||||
"""Performs 3D transposed convolution without activation function.
|
||||
If followed by batch normalization, set use_bias=False.
|
||||
"""
|
||||
return tf.layers.conv3d_transpose(
|
||||
inputs=inputs,
|
||||
filters=filters,
|
||||
kernel_size=kernel_size,
|
||||
strides=strides,
|
||||
padding='same',
|
||||
use_bias=use_bias,
|
||||
kernel_initializer=conf_basic_ops['kernel_initializer'],
|
||||
name=name,
|
||||
)
|
||||
|
||||
def batch_norm(inputs, training, name=None):
|
||||
"""Performs a batch normalization.
|
||||
We set fused=True for a significant performance boost.
|
||||
See https://www.tensorflow.org/performance/performance_guide#common_fused_ops
|
||||
"""
|
||||
return tf.layers.batch_normalization(
|
||||
inputs=inputs,
|
||||
momentum=conf_basic_ops['momentum'],
|
||||
epsilon=conf_basic_ops['epsilon'],
|
||||
center=True,
|
||||
scale=True,
|
||||
training=training,
|
||||
fused=True,
|
||||
name=name,
|
||||
)
|
||||
|
||||
def relu(inputs, name=None):
|
||||
return tf.nn.relu(inputs, name=name) if conf_basic_ops['relu_type'] == 'relu' \
|
||||
else tf.nn.relu6(inputs, name=name)
|
||||
|
|
@ -0,0 +1,539 @@
|
|||
import os, cv2
|
||||
import numpy as np
|
||||
from network_configure import conf_unet
|
||||
from network import *
|
||||
from utils.predict_utils import get_coord, PercentileNormalizer, PadAndCropResizer
|
||||
from utils.train_utils import augment_patch
|
||||
from utils import train_utils
|
||||
|
||||
# UNet implementation inherited from GVTNets: https://github.com/zhengyang-wang/GVTNets
|
||||
training_config = {'base_learning_rate': 0.0004,
|
||||
'lr_decay_steps':5e3,
|
||||
'lr_decay_rate':0.5,
|
||||
'lr_staircase':True}
|
||||
|
||||
class Noise2Same(object):
|
||||
|
||||
def __init__(self, base_dir, name,
|
||||
dim=2, in_channels=1, lmbd=None,
|
||||
masking='gaussian', mask_perc=0.5,
|
||||
opt_config=training_config, **kwargs):
|
||||
|
||||
self.base_dir = base_dir # model direction
|
||||
self.name = name # model name
|
||||
self.dim = dim # image dimension
|
||||
self.in_channels = in_channels # image channels
|
||||
self.lmbd = lmbd # lambda in loss fn
|
||||
self.masking = masking
|
||||
self.mask_perc = mask_perc
|
||||
|
||||
self.opt_config = opt_config
|
||||
conf_unet['dimension'] = '%dD'%dim
|
||||
self.net = UNet(conf_unet)
|
||||
|
||||
def _model_fn(self, features, labels, mode):
|
||||
conv_op = convolution_2D if self.dim==2 else convolution_3D
|
||||
axis = {3:[1,2,3,4], 2:[1,2,3]}[self.dim]
|
||||
|
||||
def image_summary(img):
|
||||
return tf.reduce_max(img, axis=1) if self.dim == 3 else img
|
||||
|
||||
# Local average excluding the center pixel (donut)
|
||||
def mask_kernel(features):
|
||||
kernel = (np.array([[0.5, 1.0, 0.5], [1.0, 0.0, 1.0], [0.5, 1.0, 0.5]])
|
||||
if self.dim == 2 else
|
||||
np.array([[[0, 0.5, 0], [0.5, 1.0, 0.5], [0, 0.5, 0]],
|
||||
[[0.5, 1.0, 0.5], [1.0, 0.0, 1.0], [0.5, 1.0, 0.5]],
|
||||
[[0, 0.5, 0], [0.5, 1.0, 0.5], [0, 0.5, 0]]]))
|
||||
kernel = (kernel/kernel.sum())
|
||||
kernels = np.empty([3, 3, self.in_channels, self.in_channels])
|
||||
for i in range(self.in_channels):
|
||||
kernels[:,:,i,i] = kernel
|
||||
nn_conv_op = tf.nn.conv2d if self.dim == 2 else tf.nn.conv3d
|
||||
return nn_conv_op(features, tf.constant(kernels.astype('float32')),
|
||||
[1]*self.dim+[1,1], padding='SAME')
|
||||
|
||||
if not mode == tf.estimator.ModeKeys.PREDICT:
|
||||
noise, mask = tf.split(labels, [self.in_channels, self.in_channels], -1)
|
||||
|
||||
if self.masking == 'gaussian':
|
||||
masked_features = (1 - mask) * features + mask * noise
|
||||
elif self.masking == 'donut':
|
||||
masked_features = (1 - mask) * features + mask * mask_kernel(features)
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
# Prediction from masked input
|
||||
with tf.variable_scope('main_unet', reuse=tf.compat.v1.AUTO_REUSE):
|
||||
out = self.net(masked_features, mode == tf.estimator.ModeKeys.TRAIN)
|
||||
out = batch_norm(out, mode == tf.estimator.ModeKeys.TRAIN, 'unet_out')
|
||||
out = relu(out)
|
||||
preds = conv_op(out, self.in_channels, 1, 1, False, name = 'out_conv')
|
||||
|
||||
# Prediction from full input
|
||||
with tf.variable_scope('main_unet', reuse=tf.compat.v1.AUTO_REUSE):
|
||||
rawout = self.net(features, mode == tf.estimator.ModeKeys.TRAIN)
|
||||
rawout = batch_norm(rawout, mode == tf.estimator.ModeKeys.TRAIN, 'unet_out')
|
||||
rawout = relu(rawout)
|
||||
rawpreds = conv_op(rawout, self.in_channels, 1, 1, False, name = 'out_conv')
|
||||
|
||||
# Loss components
|
||||
rec_mse = tf.reduce_mean(tf.square(rawpreds - features), axis=None)
|
||||
inv_mse = tf.reduce_sum(tf.square(rawpreds - preds) * mask) / tf.reduce_sum(mask)
|
||||
bsp_mse = tf.reduce_sum(tf.square(features - preds) * mask) / tf.reduce_sum(mask)
|
||||
|
||||
# Tensorboard display
|
||||
tf.summary.image('1_inputs', image_summary(features), max_outputs=3)
|
||||
tf.summary.image('2_raw_predictions', image_summary(rawpreds), max_outputs=3)
|
||||
tf.summary.image('3_mask', image_summary(mask), max_outputs=3)
|
||||
tf.summary.image('4_masked_predictions', image_summary(preds), max_outputs=3)
|
||||
tf.summary.image('5_difference', image_summary(rawpreds-preds), max_outputs=3)
|
||||
tf.summary.image('6_rec_error', image_summary(preds-features), max_outputs=3)
|
||||
tf.summary.scalar('reconstruction', rec_mse, family='loss_metric')
|
||||
tf.summary.scalar('invariance', inv_mse, family='loss_metric')
|
||||
tf.summary.scalar('blind_spot', bsp_mse, family='loss_metric')
|
||||
|
||||
else:
|
||||
with tf.variable_scope('main_unet'):
|
||||
out = self.net(features, mode == tf.estimator.ModeKeys.TRAIN)
|
||||
out = batch_norm(out, mode == tf.estimator.ModeKeys.TRAIN, 'unet_out')
|
||||
out = relu(out)
|
||||
preds = conv_op(out, self.in_channels, 1, 1, False, name = 'out_conv')
|
||||
return tf.estimator.EstimatorSpec(mode=mode, predictions=preds)
|
||||
|
||||
lmbd = 2 if self.lmbd is None else self.lmbd
|
||||
loss = rec_mse + lmbd*tf.sqrt(inv_mse)
|
||||
|
||||
if mode == tf.estimator.ModeKeys.TRAIN:
|
||||
global_step = tf.train.get_or_create_global_step()
|
||||
learning_rate = tf.train.exponential_decay(self.opt_config['base_learning_rate'],
|
||||
global_step,
|
||||
self.opt_config['lr_decay_steps'],
|
||||
self.opt_config['lr_decay_rate'],
|
||||
self.opt_config['lr_staircase'])
|
||||
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
|
||||
|
||||
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS, scope='main_unet')
|
||||
with tf.control_dependencies(update_ops):
|
||||
train_op = optimizer.minimize(loss, global_step)
|
||||
else:
|
||||
train_op = None
|
||||
|
||||
metrics = {'loss_metric/invariance':tf.metrics.mean(inv_mse),
|
||||
'loss_metric/blind_spot':tf.metrics.mean(bsp_mse),
|
||||
'loss_metric/reconstruction':tf.metrics.mean(rec_mse)}
|
||||
|
||||
return tf.estimator.EstimatorSpec(mode=mode, predictions=preds, loss=loss, train_op=train_op,
|
||||
eval_metric_ops=metrics)
|
||||
|
||||
|
||||
def _input_fn(self, sources, patch_size, batch_size, is_train=True):
|
||||
# Stratified sampling inherited from Noise2Void: https://github.com/juglab/n2v
|
||||
get_stratified_coords = getattr(train_utils, 'get_stratified_coords%dD'%self.dim)
|
||||
rand_float_coords = getattr(train_utils, 'rand_float_coords%dD'%self.dim)
|
||||
|
||||
def generator():
|
||||
while(True):
|
||||
source = sources[np.random.randint(len(sources))]
|
||||
valid_shape = source.shape[:-1] - np.array(patch_size)
|
||||
if any([s<=0 for s in valid_shape]):
|
||||
source_patch = augment_patch(source)
|
||||
else:
|
||||
coords = [np.random.randint(0, shape_i+1) for shape_i in valid_shape]
|
||||
s = tuple([slice(coord, coord+size) for coord, size in zip(coords, patch_size)])
|
||||
source_patch = augment_patch(source[s])
|
||||
|
||||
mask = np.zeros_like(source_patch)
|
||||
for c in range(self.in_channels):
|
||||
boxsize = np.round(np.sqrt(100/self.mask_perc)).astype(np.int)
|
||||
maskcoords = get_stratified_coords(rand_float_coords(boxsize),
|
||||
box_size=boxsize, shape=tuple(patch_size))
|
||||
indexing = maskcoords + (c,)
|
||||
mask[indexing] = 1.0
|
||||
|
||||
noise_patch = np.concatenate([np.random.normal(0, 0.2, source_patch.shape), mask], axis=-1)
|
||||
yield source_patch, noise_patch
|
||||
|
||||
def generator_val():
|
||||
for idx in range(len(sources)):
|
||||
source_patch = sources[idx]
|
||||
patch_size = source_patch.shape[:-1]
|
||||
boxsize = np.round(np.sqrt(100/self.mask_perc)).astype(np.int)
|
||||
maskcoords = get_stratified_coords(rand_float_coords(boxsize),
|
||||
box_size=boxsize, shape=tuple(patch_size))
|
||||
indexing = maskcoords + (0,)
|
||||
mask = np.zeros_like(source_patch)
|
||||
mask[indexing] = 1.0
|
||||
noise_patch = np.concatenate([np.random.normal(0, 0.2, source_patch.shape), mask], axis=-1)
|
||||
yield source_patch, noise_patch
|
||||
|
||||
output_types = (tf.float32, tf.float32)
|
||||
output_shapes = (tf.TensorShape(list(patch_size) + [self.in_channels]),
|
||||
tf.TensorShape(list(patch_size) + [self.in_channels*2]))
|
||||
gen = generator if is_train else generator_val
|
||||
dataset = tf.data.Dataset.from_generator(gen, output_types=output_types, output_shapes=output_shapes)
|
||||
dataset = dataset.batch(batch_size).prefetch(tf.data.experimental.AUTOTUNE)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
def train(self, source_lst, patch_size, validation=None, batch_size=64, save_steps=100, log_steps=100, steps=50000):
|
||||
assert len(patch_size)==self.dim
|
||||
assert len(source_lst[0].shape)==self.dim + 1
|
||||
assert source_lst[0].shape[-1]==self.in_channels
|
||||
|
||||
ses_config = tf.ConfigProto()
|
||||
ses_config.gpu_options.allow_growth = True
|
||||
|
||||
run_config = tf.estimator.RunConfig(model_dir=self.base_dir+'/'+self.name,
|
||||
save_checkpoints_steps=save_steps,
|
||||
session_config=ses_config,
|
||||
log_step_count_steps=log_steps,
|
||||
save_summary_steps=log_steps,
|
||||
keep_checkpoint_max=2)
|
||||
|
||||
estimator = tf.estimator.Estimator(model_fn=self._model_fn,
|
||||
model_dir=self.base_dir+'/'+self.name,
|
||||
config=run_config)
|
||||
|
||||
input_fn = lambda: self._input_fn(source_lst, patch_size, batch_size=batch_size)
|
||||
|
||||
if validation is not None:
|
||||
train_spec = tf.estimator.TrainSpec(input_fn=input_fn, max_steps=steps)
|
||||
val_input_fn = lambda: self._input_fn(validation.astype('float32'),
|
||||
validation.shape[1:-1],
|
||||
batch_size=4,
|
||||
is_train=False)
|
||||
eval_spec = tf.estimator.EvalSpec(input_fn=val_input_fn, throttle_secs=120)
|
||||
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
|
||||
else:
|
||||
estimator.train(input_fn=input_fn, steps=steps)
|
||||
|
||||
|
||||
# Used for single image prediction
|
||||
def predict(self, image, resizer=PadAndCropResizer(), checkpoint_path=None,
|
||||
im_mean=None, im_std=None):
|
||||
|
||||
tf.logging.set_verbosity(tf.logging.ERROR)
|
||||
estimator = tf.estimator.Estimator(model_fn=self._model_fn,
|
||||
model_dir=self.base_dir+'/'+self.name)
|
||||
|
||||
im_mean, im_std = ((image.mean(), image.std()) if im_mean is None or im_std is None else (im_mean, im_std))
|
||||
image = (image - im_mean)/im_std
|
||||
if self.in_channels == 1:
|
||||
image = resizer.before(image, 2 ** (self.net.depth), exclude=None)
|
||||
input_fn = tf.estimator.inputs.numpy_input_fn(x=image[None, ..., None], batch_size=1, num_epochs=1, shuffle=False)
|
||||
image = list(estimator.predict(input_fn=input_fn, checkpoint_path=checkpoint_path))[0][..., 0]
|
||||
image = resizer.after(image, exclude=None)
|
||||
else:
|
||||
image = resizer.before(image, 2 ** (self.net.depth), exclude=-1)
|
||||
input_fn = tf.estimator.inputs.numpy_input_fn(x=image[None], batch_size=1, num_epochs=1, shuffle=False)
|
||||
image = list(estimator.predict(input_fn=input_fn, checkpoint_path=checkpoint_path))[0]
|
||||
image = resizer.after(image, exclude=-1)
|
||||
image = image*im_std + im_mean
|
||||
|
||||
return image
|
||||
|
||||
# Used for batch images prediction
|
||||
def batch_predict(self, images, resizer=PadAndCropResizer(), checkpoint_path=None,
|
||||
im_mean=None, im_std=None, batch_size=32):
|
||||
|
||||
tf.logging.set_verbosity(tf.logging.ERROR)
|
||||
estimator = tf.estimator.Estimator(model_fn=self._model_fn,
|
||||
model_dir=self.base_dir+'/'+self.name)
|
||||
|
||||
im_mean, im_std = ((images.mean(), images.std()) if im_mean is None or im_std is None else (im_mean, im_std))
|
||||
|
||||
images = (images - im_mean)/im_std
|
||||
images = resizer.before(images, 2 ** (self.net.depth), exclude=0)
|
||||
input_fn = tf.estimator.inputs.numpy_input_fn(x=images[ ..., None], batch_size=batch_size, num_epochs=1, shuffle=False)
|
||||
images = np.stack(list(estimator.predict(input_fn=input_fn, checkpoint_path=checkpoint_path)))[..., 0]
|
||||
images = resizer.after(images, exclude=0)
|
||||
images = images*im_std + im_mean
|
||||
|
||||
return images
|
||||
|
||||
# Used for extremely large input images
|
||||
def crop_predict(self, image, size, margin, resizer=PadAndCropResizer(), checkpoint_path=None,
|
||||
im_mean=None, im_std=None):
|
||||
|
||||
tf.logging.set_verbosity(tf.logging.ERROR)
|
||||
estimator = tf.estimator.Estimator(model_fn=self._model_fn,
|
||||
model_dir=self.base_dir+'/'+self.name)
|
||||
|
||||
im_mean, im_std = ((image.mean(), image.std()) if im_mean is None or im_std is None else (im_mean, im_std))
|
||||
image = (image - im_mean)/im_std
|
||||
out_image = np.empty(image.shape, dtype='float32')
|
||||
for src_s, trg_s, mrg_s in get_coord(image.shape, size, margin):
|
||||
patch = resizer.before(image[src_s], 2 ** (self.net.depth), exclude=None)
|
||||
input_fn = tf.estimator.inputs.numpy_input_fn(x=patch[None, ..., None], batch_size=1, num_epochs=1, shuffle=False)
|
||||
patch = list(estimator.predict(input_fn=input_fn, checkpoint_path=checkpoint_path))[0][..., 0]
|
||||
patch = resizer.after(patch, exclude=None)
|
||||
out_image[trg_s] = patch[mrg_s]
|
||||
|
||||
image = out_image*im_std + im_mean
|
||||
|
||||
return image
|
||||
|
||||
class Noise2SamePro(object):
|
||||
|
||||
def __init__(self, base_dir, name,
|
||||
dim=2, in_channels=1, lmbd=None,
|
||||
masking='gaussian', mask_perc=0.5,
|
||||
opt_config=training_config, **kwargs):
|
||||
|
||||
self.base_dir = base_dir # model direction
|
||||
self.name = name # model name
|
||||
self.dim = dim # image dimension
|
||||
self.in_channels = in_channels # image channels
|
||||
self.lmbd = lmbd # lambda in loss fn
|
||||
self.masking = masking
|
||||
self.mask_perc = mask_perc
|
||||
|
||||
self.opt_config = opt_config
|
||||
conf_unet['dimension'] = '%dD'%dim
|
||||
self.net = UNet(conf_unet)
|
||||
|
||||
def _model_fn(self, features, labels, mode):
|
||||
conv_op = convolution_2D if self.dim==2 else convolution_3D
|
||||
axis = {3:[1,2,3,4], 2:[1,2,3]}[self.dim]
|
||||
|
||||
def image_summary(img):
|
||||
return tf.reduce_max(img, axis=1) if self.dim == 3 else img
|
||||
|
||||
# Local average excluding the center pixel (donut)
|
||||
def mask_kernel(features):
|
||||
kernel = (np.array([[0.5, 1.0, 0.5], [1.0, 0.0, 1.0], [0.5, 1.0, 0.5]])
|
||||
if self.dim == 2 else
|
||||
np.array([[[0, 0.5, 0], [0.5, 1.0, 0.5], [0, 0.5, 0]],
|
||||
[[0.5, 1.0, 0.5], [1.0, 0.0, 1.0], [0.5, 1.0, 0.5]],
|
||||
[[0, 0.5, 0], [0.5, 1.0, 0.5], [0, 0.5, 0]]]))
|
||||
kernel = (kernel/kernel.sum())
|
||||
kernels = np.empty([3, 3, self.in_channels, self.in_channels])
|
||||
for i in range(self.in_channels):
|
||||
kernels[:,:,i,i] = kernel
|
||||
nn_conv_op = tf.nn.conv2d if self.dim == 2 else tf.nn.conv3d
|
||||
return nn_conv_op(features, tf.constant(kernels.astype('float32')),
|
||||
[1]*self.dim+[1,1], padding='SAME')
|
||||
|
||||
if not mode == tf.estimator.ModeKeys.PREDICT:
|
||||
noise, mask = tf.split(labels, [self.in_channels, self.in_channels], -1)
|
||||
|
||||
if self.masking == 'gaussian':
|
||||
masked_features = (1 - mask) * features + mask * noise
|
||||
elif self.masking == 'donut':
|
||||
masked_features = (1 - mask) * features + mask * mask_kernel(features)
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
# Prediction from masked input
|
||||
with tf.variable_scope('main_unet', reuse=tf.compat.v1.AUTO_REUSE):
|
||||
out = self.net(masked_features, mode == tf.estimator.ModeKeys.TRAIN)
|
||||
out = batch_norm(out, mode == tf.estimator.ModeKeys.TRAIN, 'unet_out')
|
||||
out = relu(out)
|
||||
preds = conv_op(out, self.in_channels, 1, 1, False, name = 'out_conv')
|
||||
|
||||
# Prediction from full input
|
||||
with tf.variable_scope('main_unet', reuse=tf.compat.v1.AUTO_REUSE):
|
||||
rawout = self.net(features, mode == tf.estimator.ModeKeys.TRAIN)
|
||||
rawout = batch_norm(rawout, mode == tf.estimator.ModeKeys.TRAIN, 'unet_out')
|
||||
rawout = relu(rawout)
|
||||
rawpreds = conv_op(rawout, self.in_channels, 1, 1, False, name = 'out_conv')
|
||||
|
||||
# Loss components
|
||||
rec_mse = tf.reduce_mean(tf.square(rawpreds - features), axis=None)
|
||||
inv_mse = tf.reduce_sum(tf.square(rawpreds - preds) * mask) / tf.reduce_sum(mask)
|
||||
bsp_mse = tf.reduce_sum(tf.square(features - preds) * mask) / tf.reduce_sum(mask)
|
||||
|
||||
# Tensorboard display
|
||||
tf.summary.image('1_inputs', image_summary(features), max_outputs=3)
|
||||
tf.summary.image('2_raw_predictions', image_summary(rawpreds), max_outputs=3)
|
||||
tf.summary.image('3_mask', image_summary(mask), max_outputs=3)
|
||||
tf.summary.image('4_masked_predictions', image_summary(preds), max_outputs=3)
|
||||
tf.summary.image('5_difference', image_summary(rawpreds-preds), max_outputs=3)
|
||||
tf.summary.image('6_rec_error', image_summary(preds-features), max_outputs=3)
|
||||
tf.summary.scalar('reconstruction', rec_mse, family='loss_metric')
|
||||
tf.summary.scalar('invariance', inv_mse, family='loss_metric')
|
||||
tf.summary.scalar('blind_spot', bsp_mse, family='loss_metric')
|
||||
|
||||
else:
|
||||
with tf.variable_scope('main_unet'):
|
||||
out = self.net(features, mode == tf.estimator.ModeKeys.TRAIN)
|
||||
out = batch_norm(out, mode == tf.estimator.ModeKeys.TRAIN, 'unet_out')
|
||||
out = relu(out)
|
||||
preds = conv_op(out, self.in_channels, 1, 1, False, name = 'out_conv')
|
||||
return tf.estimator.EstimatorSpec(mode=mode, predictions=preds)
|
||||
|
||||
lmbd = tf.sqrt(rec_mse)
|
||||
loss = rec_mse + 2*lmbd*tf.sqrt(inv_mse)
|
||||
|
||||
if mode == tf.estimator.ModeKeys.TRAIN:
|
||||
global_step = tf.train.get_or_create_global_step()
|
||||
learning_rate = tf.train.exponential_decay(self.opt_config['base_learning_rate'],
|
||||
global_step,
|
||||
self.opt_config['lr_decay_steps'],
|
||||
self.opt_config['lr_decay_rate'],
|
||||
self.opt_config['lr_staircase'])
|
||||
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
|
||||
|
||||
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS, scope='main_unet')
|
||||
with tf.control_dependencies(update_ops):
|
||||
train_op = optimizer.minimize(loss, global_step)
|
||||
else:
|
||||
train_op = None
|
||||
|
||||
metrics = {'loss_metric/invariance':tf.metrics.mean(inv_mse),
|
||||
'loss_metric/blind_spot':tf.metrics.mean(bsp_mse),
|
||||
'loss_metric/reconstruction':tf.metrics.mean(rec_mse)}
|
||||
|
||||
return tf.estimator.EstimatorSpec(mode=mode, predictions=preds, loss=loss, train_op=train_op,
|
||||
eval_metric_ops=metrics)
|
||||
|
||||
|
||||
def _input_fn(self, sources, patch_size, batch_size, is_train=True):
|
||||
# Stratified sampling inherited from Noise2Void: https://github.com/juglab/n2v
|
||||
get_stratified_coords = getattr(train_utils, 'get_stratified_coords%dD'%self.dim)
|
||||
rand_float_coords = getattr(train_utils, 'rand_float_coords%dD'%self.dim)
|
||||
|
||||
def generator():
|
||||
while(True):
|
||||
source = sources[np.random.randint(len(sources))]
|
||||
valid_shape = source.shape[:-1] - np.array(patch_size)
|
||||
if any([s<=0 for s in valid_shape]):
|
||||
source_patch = augment_patch(source)
|
||||
else:
|
||||
coords = [np.random.randint(0, shape_i+1) for shape_i in valid_shape]
|
||||
s = tuple([slice(coord, coord+size) for coord, size in zip(coords, patch_size)])
|
||||
source_patch = augment_patch(source[s])
|
||||
|
||||
mask = np.zeros_like(source_patch)
|
||||
for c in range(self.in_channels):
|
||||
boxsize = np.round(np.sqrt(100/self.mask_perc)).astype(np.int)
|
||||
maskcoords = get_stratified_coords(rand_float_coords(boxsize),
|
||||
box_size=boxsize, shape=tuple(patch_size))
|
||||
indexing = maskcoords + (c,)
|
||||
mask[indexing] = 1.0
|
||||
|
||||
noise_patch = np.concatenate([np.random.normal(0, 0.2, source_patch.shape), mask], axis=-1)
|
||||
yield source_patch, noise_patch
|
||||
|
||||
def generator_val():
|
||||
for idx in range(len(sources)):
|
||||
source_patch = sources[idx]
|
||||
patch_size = source_patch.shape[:-1]
|
||||
boxsize = np.round(np.sqrt(100/self.mask_perc)).astype(np.int)
|
||||
maskcoords = get_stratified_coords(rand_float_coords(boxsize),
|
||||
box_size=boxsize, shape=tuple(patch_size))
|
||||
indexing = maskcoords + (0,)
|
||||
mask = np.zeros_like(source_patch)
|
||||
mask[indexing] = 1.0
|
||||
noise_patch = np.concatenate([np.random.normal(0, 0.2, source_patch.shape), mask], axis=-1)
|
||||
yield source_patch, noise_patch
|
||||
|
||||
output_types = (tf.float32, tf.float32)
|
||||
output_shapes = (tf.TensorShape(list(patch_size) + [self.in_channels]),
|
||||
tf.TensorShape(list(patch_size) + [self.in_channels*2]))
|
||||
gen = generator if is_train else generator_val
|
||||
dataset = tf.data.Dataset.from_generator(gen, output_types=output_types, output_shapes=output_shapes)
|
||||
dataset = dataset.batch(batch_size).prefetch(tf.data.experimental.AUTOTUNE)
|
||||
|
||||
return dataset
|
||||
|
||||
|
||||
def train(self, source_lst, patch_size, validation=None, batch_size=64, save_steps=100, log_steps=100, steps=50000):
|
||||
assert len(patch_size)==self.dim
|
||||
assert len(source_lst[0].shape)==self.dim + 1
|
||||
assert source_lst[0].shape[-1]==self.in_channels
|
||||
|
||||
ses_config = tf.ConfigProto()
|
||||
ses_config.gpu_options.allow_growth = True
|
||||
|
||||
run_config = tf.estimator.RunConfig(model_dir=self.base_dir+'/'+self.name,
|
||||
save_checkpoints_steps=save_steps,
|
||||
session_config=ses_config,
|
||||
log_step_count_steps=log_steps,
|
||||
save_summary_steps=log_steps,
|
||||
keep_checkpoint_max=2)
|
||||
|
||||
estimator = tf.estimator.Estimator(model_fn=self._model_fn,
|
||||
model_dir=self.base_dir+'/'+self.name,
|
||||
config=run_config)
|
||||
|
||||
input_fn = lambda: self._input_fn(source_lst, patch_size, batch_size=batch_size)
|
||||
|
||||
if validation is not None:
|
||||
train_spec = tf.estimator.TrainSpec(input_fn=input_fn, max_steps=steps)
|
||||
val_input_fn = lambda: self._input_fn(validation.astype('float32'),
|
||||
validation.shape[1:-1],
|
||||
batch_size=4,
|
||||
is_train=False)
|
||||
eval_spec = tf.estimator.EvalSpec(input_fn=val_input_fn, throttle_secs=120)
|
||||
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
|
||||
else:
|
||||
estimator.train(input_fn=input_fn, steps=steps)
|
||||
|
||||
|
||||
# Used for single image prediction
|
||||
def predict(self, image, resizer=PadAndCropResizer(), checkpoint_path=None,
|
||||
im_mean=None, im_std=None):
|
||||
|
||||
tf.logging.set_verbosity(tf.logging.ERROR)
|
||||
estimator = tf.estimator.Estimator(model_fn=self._model_fn,
|
||||
model_dir=self.base_dir+'/'+self.name)
|
||||
|
||||
im_mean, im_std = ((image.mean(), image.std()) if im_mean is None or im_std is None else (im_mean, im_std))
|
||||
image = (image - im_mean)/im_std
|
||||
if self.in_channels == 1:
|
||||
image = resizer.before(image, 2 ** (self.net.depth), exclude=None)
|
||||
input_fn = tf.estimator.inputs.numpy_input_fn(x=image[None, ..., None], batch_size=1, num_epochs=1, shuffle=False)
|
||||
image = list(estimator.predict(input_fn=input_fn, checkpoint_path=checkpoint_path))[0][..., 0]
|
||||
image = resizer.after(image, exclude=None)
|
||||
else:
|
||||
image = resizer.before(image, 2 ** (self.net.depth), exclude=-1)
|
||||
input_fn = tf.estimator.inputs.numpy_input_fn(x=image[None], batch_size=1, num_epochs=1, shuffle=False)
|
||||
image = list(estimator.predict(input_fn=input_fn, checkpoint_path=checkpoint_path))[0]
|
||||
image = resizer.after(image, exclude=-1)
|
||||
image = image*im_std + im_mean
|
||||
|
||||
return image
|
||||
|
||||
# Used for batch images prediction
|
||||
def batch_predict(self, images, resizer=PadAndCropResizer(), checkpoint_path=None,
|
||||
im_mean=None, im_std=None, batch_size=32):
|
||||
|
||||
tf.logging.set_verbosity(tf.logging.ERROR)
|
||||
estimator = tf.estimator.Estimator(model_fn=self._model_fn,
|
||||
model_dir=self.base_dir+'/'+self.name)
|
||||
|
||||
im_mean, im_std = ((images.mean(), images.std()) if im_mean is None or im_std is None else (im_mean, im_std))
|
||||
|
||||
images = (images - im_mean)/im_std
|
||||
images = resizer.before(images, 2 ** (self.net.depth), exclude=0)
|
||||
input_fn = tf.estimator.inputs.numpy_input_fn(x=images[ ..., None], batch_size=batch_size, num_epochs=1, shuffle=False)
|
||||
images = np.stack(list(estimator.predict(input_fn=input_fn, checkpoint_path=checkpoint_path)))[..., 0]
|
||||
images = resizer.after(images, exclude=0)
|
||||
images = images*im_std + im_mean
|
||||
|
||||
return images
|
||||
|
||||
# Used for extremely large input images
|
||||
def crop_predict(self, image, size, margin, resizer=PadAndCropResizer(), checkpoint_path=None,
|
||||
im_mean=None, im_std=None):
|
||||
|
||||
tf.logging.set_verbosity(tf.logging.ERROR)
|
||||
estimator = tf.estimator.Estimator(model_fn=self._model_fn,
|
||||
model_dir=self.base_dir+'/'+self.name)
|
||||
|
||||
im_mean, im_std = ((image.mean(), image.std()) if im_mean is None or im_std is None else (im_mean, im_std))
|
||||
image = (image - im_mean)/im_std
|
||||
out_image = np.empty(image.shape, dtype='float32')
|
||||
for src_s, trg_s, mrg_s in get_coord(image.shape, size, margin):
|
||||
patch = resizer.before(image[src_s], 2 ** (self.net.depth), exclude=None)
|
||||
input_fn = tf.estimator.inputs.numpy_input_fn(x=patch[None, ..., None], batch_size=1, num_epochs=1, shuffle=False)
|
||||
patch = list(estimator.predict(input_fn=input_fn, checkpoint_path=checkpoint_path))[0][..., 0]
|
||||
patch = resizer.after(patch, exclude=None)
|
||||
out_image[trg_s] = patch[mrg_s]
|
||||
|
||||
image = out_image*im_std + im_mean
|
||||
|
||||
return image
|
||||
|
|
@ -0,0 +1,117 @@
|
|||
import logging, os
|
||||
logging.disable(logging.WARNING)
|
||||
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
|
||||
|
||||
import tensorflow as tf
|
||||
from basic_ops import *
|
||||
from resnet_module import *
|
||||
|
||||
|
||||
"""This script generates the U-Net architecture according to conf_unet.
|
||||
"""
|
||||
|
||||
class UNet(object):
|
||||
def __init__(self, conf_unet):
|
||||
self.depth = conf_unet['depth']
|
||||
self.dimension = conf_unet['dimension']
|
||||
self.first_output_filters = conf_unet['first_output_filters']
|
||||
self.encoding_block_sizes = conf_unet['encoding_block_sizes']
|
||||
self.downsampling = conf_unet['downsampling']
|
||||
self.decoding_block_sizes = conf_unet['decoding_block_sizes']
|
||||
self.skip_method = conf_unet['skip_method']
|
||||
|
||||
def __call__(self, inputs, training):
|
||||
"""Add operations to classify a batch of input images.
|
||||
|
||||
Args:
|
||||
inputs: A Tensor representing a batch of input images.
|
||||
training: A boolean. Set to True to add operations required only when
|
||||
training the classifier.
|
||||
|
||||
Returns:
|
||||
A logits Tensor with shape [<batch_size>, self.num_classes].
|
||||
"""
|
||||
|
||||
return self._build_network(inputs, training)
|
||||
|
||||
|
||||
################################################################################
|
||||
# Composite blocks building the network
|
||||
################################################################################
|
||||
def _build_network(self, inputs, training):
|
||||
# first_convolution
|
||||
if self.dimension == '2D':
|
||||
convolution = convolution_2D
|
||||
elif self.dimension == '3D':
|
||||
convolution = convolution_3D
|
||||
inputs = convolution(inputs, self.first_output_filters, 3, 1, False, 'first_convolution')
|
||||
|
||||
# encoding_block_1
|
||||
with tf.variable_scope('encoding_block_1'):
|
||||
for block_index in range(0, self.encoding_block_sizes[0]):
|
||||
inputs = res_block(inputs, self.first_output_filters, training, self.dimension,
|
||||
'res_%d' % block_index)
|
||||
|
||||
# encoding_block_i (down) = downsampling + zero or more res_block, i = 2, 3, ..., depth
|
||||
skip_inputs = [] # for identity skip connections
|
||||
for i in range(2, self.depth+1):
|
||||
skip_inputs.append(inputs)
|
||||
with tf.variable_scope('encoding_block_%d' % i):
|
||||
output_filters = self.first_output_filters * (2**(i-1))
|
||||
|
||||
# downsampling
|
||||
downsampling_func = self._get_downsampling_function(self.downsampling[i-2])
|
||||
inputs = downsampling_func(inputs, output_filters, training, self.dimension,
|
||||
'downsampling')
|
||||
|
||||
for block_index in range(0, self.encoding_block_sizes[i-1]):
|
||||
inputs = res_block(inputs, output_filters, training, self.dimension,
|
||||
'res_%d' % block_index)
|
||||
|
||||
# bottom_block = a combination of same_gto and res_block
|
||||
with tf.variable_scope('bottom_block'):
|
||||
output_filters = self.first_output_filters * (2**(self.depth-1))
|
||||
for block_index in range(0, 1):
|
||||
current_func = res_block
|
||||
inputs = current_func(inputs, output_filters, training, self.dimension,
|
||||
'block_%d' % block_index)
|
||||
|
||||
"""
|
||||
Note: Identity skip connections are between the output of encoding_block_i and
|
||||
the output of upsampling in decoding_block_i, i = 1, 2, ..., depth-1.
|
||||
skip_inputs[i] is the output of encoding_block_i now.
|
||||
len(skip_inputs) == depth - 1
|
||||
skip_inputs[depth-2] should be combined during decoding_block_depth-1
|
||||
skip_inputs[0] should be combined during decoding_block_1
|
||||
"""
|
||||
|
||||
# decoding_block_j (up) = upsampling + zero or more res_block, j = depth-1, depth-2, ..., 1
|
||||
for j in range(self.depth-1, 0, -1):
|
||||
with tf.variable_scope('decoding_block_%d' % j):
|
||||
output_filters = self.first_output_filters * (2**(j-1))
|
||||
|
||||
# upsampling
|
||||
upsampling_func = up_transposed_convolution
|
||||
inputs = upsampling_func(inputs, output_filters, training, self.dimension,
|
||||
'upsampling')
|
||||
|
||||
# combine with skip connections
|
||||
if self.skip_method == 'add':
|
||||
inputs = tf.add(inputs, skip_inputs[j-1])
|
||||
elif self.skip_method == 'concat':
|
||||
inputs = tf.concat([inputs, skip_inputs[j-1]], axis=-1)
|
||||
|
||||
for block_index in range(0, self.decoding_block_sizes[self.depth-1-j]):
|
||||
inputs = res_block(inputs, output_filters, training, self.dimension,
|
||||
'res_%d' % block_index)
|
||||
|
||||
return inputs
|
||||
|
||||
|
||||
def _get_downsampling_function(self, name):
|
||||
if name == 'down_res_block':
|
||||
return down_res_block
|
||||
elif name == 'convolution':
|
||||
return down_convolution
|
||||
else:
|
||||
raise ValueError("Unsupported function: %s." % (name))
|
||||
|
|
@ -0,0 +1,143 @@
|
|||
import logging, os
|
||||
logging.disable(logging.WARNING)
|
||||
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
|
||||
"""This is the configuration file.
|
||||
"""
|
||||
|
||||
|
||||
################################################################################
|
||||
# Settings for Basic Operaters
|
||||
################################################################################
|
||||
|
||||
conf_basic_ops = dict()
|
||||
|
||||
# kernel_initializer for convolutions and transposed convolutions
|
||||
# If None, the default initializer is the Glorot (Xavier) normal initializer.
|
||||
conf_basic_ops['kernel_initializer'] = tf.glorot_uniform_initializer()
|
||||
|
||||
# momentum for batch normalization
|
||||
conf_basic_ops['momentum'] = 0.997
|
||||
|
||||
# epsilon for batch normalization
|
||||
conf_basic_ops['epsilon'] = 1e-5
|
||||
|
||||
# String options: 'relu', 'relu6'
|
||||
conf_basic_ops['relu_type'] = 'relu'
|
||||
|
||||
################################################################################
|
||||
# Settings for Attention Modules
|
||||
################################################################################
|
||||
|
||||
# Set the attention in same_gto
|
||||
conf_attn_same = dict()
|
||||
|
||||
# Define the relationship between total_key_filters and output_filters.
|
||||
# total_key_filters = output_filters // key_ratio
|
||||
conf_attn_same['key_ratio'] = 1
|
||||
|
||||
# Define the relationship between total_value_filters and output_filters.
|
||||
# total_key_filters = output_filters // value_ratio
|
||||
conf_attn_same['value_ratio'] = 1
|
||||
|
||||
# number of heads
|
||||
conf_attn_same['num_heads'] = 2
|
||||
|
||||
# dropout rate, 0.0 means no dropout
|
||||
conf_attn_same['dropout_rate'] = 0.0
|
||||
|
||||
# whether to use softmax on attention_weights
|
||||
conf_attn_same['use_softmax'] = False
|
||||
|
||||
# whether to use bias terms in input/output transformations
|
||||
conf_attn_same['use_bias'] = True
|
||||
|
||||
# Set the attention in up_gto
|
||||
conf_attn_up = dict()
|
||||
|
||||
conf_attn_up['key_ratio'] = 1
|
||||
conf_attn_up['value_ratio'] = 1
|
||||
conf_attn_up['num_heads'] = 2
|
||||
conf_attn_up['dropout_rate'] = 0
|
||||
conf_attn_up['use_softmax'] = False
|
||||
conf_attn_up['use_bias'] = True
|
||||
|
||||
# Set the attention in down_gto
|
||||
conf_attn_down = dict()
|
||||
|
||||
conf_attn_down['key_ratio'] = 1
|
||||
conf_attn_down['value_ratio'] = 1
|
||||
conf_attn_down['num_heads'] = 2
|
||||
conf_attn_down['dropout_rate'] = 0.0
|
||||
conf_attn_down['use_softmax'] = False
|
||||
conf_attn_down['use_bias'] = True
|
||||
|
||||
################################################################################
|
||||
# Describing the U-net
|
||||
################################################################################
|
||||
|
||||
conf_unet = dict()
|
||||
|
||||
"""
|
||||
Describe your U-Net under the following framework:
|
||||
|
||||
********************************************************************************************
|
||||
layers | output_filters
|
||||
|
|
||||
first_convolution + encoding_block_1 (same) | first_output_filters
|
||||
+ encoding_block_i, i = 2, 3, ..., depth. (down) | first_output_filters*(2**(i-1))
|
||||
+ bottom_block | first_output_filters*(2**(depth-1))
|
||||
+ decoding_block_j, j = depth-1, depth-2, ..., 1 (up) | first_output_filters*(2**(j-1))
|
||||
+ output_layer
|
||||
********************************************************************************************
|
||||
|
||||
Specifically,
|
||||
encoding_block_1 (same) = one or more res_block
|
||||
encoding_block_i (down) = downsampling + zero or more res_block, i = 2, 3, ..., depth-1
|
||||
encoding_block_depth (down) = downsampling
|
||||
bottom_block = a combination of same_gto and res_block
|
||||
decoding_block_j (up) = upsampling + zero or more res_block, j = depth-1, depth-2, ..., 1
|
||||
|
||||
Identity skip connections are between the output of encoding_block_i and
|
||||
the output of upsampling in decoding_block_i, i = 1, 2, ..., depth-1.
|
||||
The combination method could be 'add' or 'concat'.
|
||||
"""
|
||||
|
||||
# Set U-Net depth.
|
||||
conf_unet['depth'] = 3
|
||||
|
||||
# Set the output_filters for first_convolution and encoding_block_1 (same).
|
||||
conf_unet['first_output_filters'] = 96
|
||||
|
||||
# Set the encoding block sizes, i.e., number of res_block in encoding_block_i, i = 1, 2, ..., depth.
|
||||
# It is an integer list whose length equals to depth.
|
||||
# The first entry should be positive since encoding_block_1 = one or more res_block.
|
||||
# The last entry should be zero since encoding_block_depth (down) = downsampling.
|
||||
conf_unet['encoding_block_sizes'] = [1, 1, 0]
|
||||
|
||||
# Set the decoding block sizes, i.e., number of res_block in decoding_block_j, j = depth-1, depth-2, ..., 1.
|
||||
# It is an integer list whose length equals to depth-1.
|
||||
conf_unet['decoding_block_sizes'] = [1, 1]
|
||||
|
||||
# Set the downsampling methods for each encoding_block_i, i = 2, 3, ..., depth.
|
||||
# It is an string list whose length equals to depth-1.
|
||||
# String options: 'down_gto_v1', 'down_gto_v2', 'down_res_block', 'convolution'
|
||||
conf_unet['downsampling'] = ['convolution', 'convolution']
|
||||
|
||||
# Set the combination method for identity skip connections
|
||||
# String options: 'add', 'concat'
|
||||
conf_unet['skip_method'] = 'concat'
|
||||
|
||||
# Set the output layer
|
||||
|
||||
|
||||
# Check
|
||||
assert conf_unet['depth'] == len(conf_unet['encoding_block_sizes'])
|
||||
assert conf_unet['encoding_block_sizes'][0] > 0
|
||||
assert conf_unet['encoding_block_sizes'][-1] == 0
|
||||
assert conf_unet['depth'] == len(conf_unet['decoding_block_sizes']) + 1
|
||||
assert conf_unet['depth'] == len(conf_unet['downsampling']) + 1
|
||||
assert conf_unet['skip_method'] in ['add', 'concat']
|
||||
|
|
@ -0,0 +1,7 @@
|
|||
tensorflow>=1.15,<2.0
|
||||
scipy
|
||||
scikit-image
|
||||
tifffile
|
||||
gdown
|
||||
opencv-python
|
||||
numpy
|
||||
|
|
@ -0,0 +1,101 @@
|
|||
import logging, os
|
||||
logging.disable(logging.WARNING)
|
||||
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
|
||||
|
||||
import tensorflow as tf
|
||||
from basic_ops import *
|
||||
|
||||
|
||||
"""This script defines non-attention same-, up-, down- modules.
|
||||
Note that pre-activation is used for residual-like blocks.
|
||||
Note that the residual block could be used for downsampling.
|
||||
"""
|
||||
|
||||
|
||||
def res_block(inputs, output_filters, training, dimension, name):
|
||||
"""Standard residual block with pre-activation.
|
||||
|
||||
Args:
|
||||
inputs: a Tensor with shape [batch, (d,) h, w, channels]
|
||||
output_filters: an integer
|
||||
training: a boolean for batch normalization and dropout
|
||||
dimension: a string, dimension of inputs/outputs -- 2D, 3D
|
||||
name: a string
|
||||
|
||||
Returns:
|
||||
A Tensor of shape [batch, (_d,) _h, _w, output_filters]
|
||||
"""
|
||||
if dimension == '2D':
|
||||
convolution = convolution_2D
|
||||
kernel_size = 3
|
||||
elif dimension == '3D':
|
||||
convolution = convolution_3D
|
||||
kernel_size = 3
|
||||
else:
|
||||
raise ValueError("Dimension (%s) must be 2D or 3D." % (dimension))
|
||||
|
||||
with tf.variable_scope(name):
|
||||
if inputs.shape[-1] == output_filters:
|
||||
shortcut = inputs
|
||||
inputs = batch_norm(inputs, training, 'batch_norm_1')
|
||||
inputs = relu(inputs, 'relu_1')
|
||||
else:
|
||||
inputs = batch_norm(inputs, training, 'batch_norm_1')
|
||||
inputs = relu(inputs, 'relu_1')
|
||||
shortcut = convolution(inputs, output_filters, 1, 1, False, 'projection_shortcut')
|
||||
inputs = convolution(inputs, output_filters, kernel_size, 1, False, 'convolution_1')
|
||||
inputs = batch_norm(inputs, training, 'batch_norm_2')
|
||||
inputs = relu(inputs, 'relu_2')
|
||||
inputs = convolution(inputs, output_filters, kernel_size, 1, False, 'convolution_2')
|
||||
return tf.add(shortcut, inputs)
|
||||
|
||||
|
||||
def down_res_block(inputs, output_filters, training, dimension, name):
|
||||
"""Standard residual block with pre-activation for downsampling."""
|
||||
if dimension == '2D':
|
||||
convolution = convolution_2D
|
||||
projection_shortcut = convolution_2D
|
||||
elif dimension == '3D':
|
||||
convolution = convolution_3D
|
||||
projection_shortcut = convolution_3D
|
||||
else:
|
||||
raise ValueError("Dimension (%s) must be 2D or 3D." % (dimension))
|
||||
|
||||
with tf.variable_scope(name):
|
||||
# The projection_shortcut should come after the first batch norm and ReLU.
|
||||
inputs = batch_norm(inputs, training, 'batch_norm_1')
|
||||
inputs = relu(inputs, 'relu_1')
|
||||
shortcut = projection_shortcut(inputs, output_filters, 1, 2, False, 'projection_shortcut')
|
||||
inputs = convolution(inputs, output_filters, 2, 2, False, 'convolution_1')
|
||||
inputs = batch_norm(inputs, training, 'batch_norm_2')
|
||||
inputs = relu(inputs, 'relu_2')
|
||||
inputs = convolution(inputs, output_filters, 3, 1, False, 'convolution_2')
|
||||
return tf.add(shortcut, inputs)
|
||||
|
||||
def down_convolution(inputs, output_filters, training, dimension, name):
|
||||
"""Use a single stride 2 convolution for downsampling."""
|
||||
if dimension == '2D':
|
||||
convolution = convolution_2D
|
||||
pool = tf.layers.max_pooling2d
|
||||
elif dimension == '3D':
|
||||
convolution = convolution_3D
|
||||
pool = tf.layers.max_pooling3d
|
||||
else:
|
||||
raise ValueError("Dimension (%s) must be 2D or 3D." % (dimension))
|
||||
|
||||
with tf.variable_scope(name):
|
||||
inputs = convolution(inputs, output_filters, 2, 2, True, 'convolution')
|
||||
return inputs
|
||||
|
||||
def up_transposed_convolution(inputs, output_filters, training, dimension, name):
|
||||
"""Use a single stride 2 transposed convolution for upsampling."""
|
||||
if dimension == '2D':
|
||||
transposed_convolution = transposed_convolution_2D
|
||||
elif dimension == '3D':
|
||||
transposed_convolution = transposed_convolution_3D
|
||||
else:
|
||||
raise ValueError("Dimension (%s) must be 2D or 3D." % (dimension))
|
||||
|
||||
with tf.variable_scope(name):
|
||||
inputs = transposed_convolution(inputs, output_filters, 2, 2, True, 'transposed_convolution')
|
||||
return inputs
|
||||
|
|
@ -0,0 +1,18 @@
|
|||
import os
|
||||
import numpy as np
|
||||
from models import Noise2Same
|
||||
|
||||
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # Adjust to choose GPU you want to use
|
||||
|
||||
def PSNR(gt, img):
|
||||
mse = np.mean(np.square(gt - img))
|
||||
return 20 * np.log10(255) - 10 * np.log10(mse)
|
||||
|
||||
model_dir = 'N2S-3000' # Adjust your model path
|
||||
data_dir = 'Denoising_data/test/'
|
||||
model = Noise2Same('trained_models/', model_dir, dim=2, in_channels=1)
|
||||
groundtruth_data = np.load(data_dir+'bsd68_groundtruth.npy', allow_pickle=True)
|
||||
test_data = np.load(data_dir+'bsd68_gaussian25.npy', allow_pickle=True)
|
||||
preds = [model.predict(d.astype('float32')) for d in test_data]
|
||||
psnrs = [PSNR(preds[idx], groundtruth_data[idx]) for idx in range(len(test_data))]
|
||||
print(np.array(psnrs).mean())
|
||||
|
|
@ -0,0 +1,18 @@
|
|||
import os
|
||||
import numpy as np
|
||||
from models import Noise2Same
|
||||
|
||||
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # Adjust to choose GPU you want to use
|
||||
|
||||
def PSNR(gt, img):
|
||||
mse = np.mean(np.square(gt - img))
|
||||
return 20 * np.log10(255) - 10 * np.log10(mse)
|
||||
|
||||
model_dir = 'N2S_PRO-8000-2' # Adjust your model path
|
||||
data_dir = 'Denoising_data/test/'
|
||||
model = Noise2Same('trained_models/', model_dir, dim=2, in_channels=1)
|
||||
groundtruth_data = np.load(data_dir+'bsd68_groundtruth.npy', allow_pickle=True)
|
||||
test_data = np.load(data_dir+'bsd68_gaussian25.npy', allow_pickle=True)
|
||||
preds = [model.predict(d.astype('float32')) for d in test_data]
|
||||
psnrs = [PSNR(preds[idx], groundtruth_data[idx]) for idx in range(len(test_data))]
|
||||
print(np.array(psnrs).mean())
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
import os
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
from models import Noise2Same
|
||||
from PIL import Image
|
||||
|
||||
os.environ['CUDA_VISIBLE_DEVICES'] = '2' # Adjust to choose GPU you want to use
|
||||
|
||||
def test_single(png_file_path, model_dir, save_path):
|
||||
image = Image.open(png_file_path).convert('L')
|
||||
image_array = np.array(image)
|
||||
model = Noise2Same('trained_models/', model_dir, dim=2, in_channels=1)
|
||||
denoised_image = model.predict(image_array.astype('float32'))
|
||||
denoised_image_pil = Image.fromarray(np.uint8(denoised_image))
|
||||
denoised_image_pil.save(save_path)
|
||||
|
||||
plt.figure(figsize=(12, 6))
|
||||
plt.subplot(1, 2, 1)
|
||||
plt.imshow(image_array, cmap='gray')
|
||||
plt.title('Original Image')
|
||||
plt.axis('off')
|
||||
plt.subplot(1, 2, 2)
|
||||
plt.imshow(denoised_image, cmap='gray')
|
||||
plt.title('Denoised Image')
|
||||
plt.axis('off')
|
||||
plt.show()
|
||||
|
||||
picture = 'man/' # Adjust path of the picture you want to test
|
||||
model_dir = 'N2S_PRO' # Adjust your model path
|
||||
test_single('test_single/' + picture + 'original_image.png', model_dir, 'test_single/' + picture + 'denoised_image.png')
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
import os
|
||||
import numpy as np
|
||||
from models import Noise2Same
|
||||
import tensorflow as tf
|
||||
import random
|
||||
|
||||
os.environ['PYTHONHASHSEED'] = '1'
|
||||
random.seed(666)
|
||||
np.random.seed(666)
|
||||
tf.set_random_seed(666)
|
||||
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # Adjust to choose GPU you want to use
|
||||
|
||||
data_dir = 'Denoising_data/'
|
||||
X = np.load(data_dir+'train/DCNN400_train_gaussian25.npy')
|
||||
X_val = np.load(data_dir+'val/DCNN400_validation_gaussian25.npy')
|
||||
X = np.array([(x - x.mean())/x.std() for x in X])
|
||||
X_val = np.array([(x - x.mean())/x.std() for x in X_val]).astype('float32')
|
||||
|
||||
model_dir = 'N2S-3000' # Set model checkpoints save path
|
||||
steps = 3000 # Set training steps
|
||||
|
||||
sgm_loss = 1 # the default sigma is 1
|
||||
model = Noise2Same('trained_models/', model_dir, dim=2, in_channels=1, lmbd=2*sgm_loss)
|
||||
model.train(X[..., None], patch_size=[64, 64], validation=X_val[..., None], batch_size=64, steps=steps)
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
import os
|
||||
import numpy as np
|
||||
from models import Noise2Same, Noise2SamePro
|
||||
import tensorflow as tf
|
||||
import random
|
||||
|
||||
os.environ['PYTHONHASHSEED'] = '1'
|
||||
random.seed(666)
|
||||
np.random.seed(666)
|
||||
tf.set_random_seed(666)
|
||||
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # Adjust to choose GPU you want to use
|
||||
|
||||
data_dir = 'Denoising_data/'
|
||||
X = np.load(data_dir+'train/DCNN400_train_gaussian25.npy')
|
||||
X_val = np.load(data_dir+'val/DCNN400_validation_gaussian25.npy')
|
||||
X = np.array([(x - x.mean())/x.std() for x in X])
|
||||
X_val = np.array([(x - x.mean())/x.std() for x in X_val]).astype('float32')
|
||||
|
||||
model_dir = 'N2S_PRO-8000-2' # Set model checkpoints save path
|
||||
steps = 8000 # Set training steps
|
||||
|
||||
sgm_loss = 1 # the default sigma is 1
|
||||
model = Noise2Same('trained_models/', model_dir, dim=2, in_channels=1, lmbd=2*sgm_loss)
|
||||
model.train(X[..., None], patch_size=[64, 64], validation=X_val[..., None], batch_size=64, steps=steps-500)
|
||||
model = Noise2SamePro('trained_models/', model_dir, dim=2, in_channels=1)
|
||||
model.train(X[..., None], patch_size=[64, 64], validation=X_val[..., None], batch_size=64, steps=steps)
|
||||
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,70 @@
|
|||
import numpy as np
|
||||
from scipy.misc import ascent
|
||||
from skimage.measure import compare_psnr, compare_mse, compare_ssim
|
||||
from .predict_utils import normalize_mi_ma
|
||||
|
||||
def normalize(x, pmin=2, pmax=99.8, axis=None, clip=False, eps=1e-20, dtype=np.float32):
|
||||
"""Percentile-based image normalization."""
|
||||
|
||||
mi = np.percentile(x,pmin,axis=axis,keepdims=True)
|
||||
ma = np.percentile(x,pmax,axis=axis,keepdims=True)
|
||||
return normalize_mi_ma(x, mi, ma, clip=clip, eps=eps, dtype=dtype)
|
||||
|
||||
def norm_minmse(gt, x, normalize_gt=True):
|
||||
"""
|
||||
normalizes and affinely scales an image pair such that the MSE is minimized
|
||||
|
||||
Parameters
|
||||
----------
|
||||
gt: ndarray
|
||||
the ground truth image
|
||||
x: ndarray
|
||||
the image that will be affinely scaled
|
||||
normalize_gt: bool
|
||||
set to True of gt image should be normalized (default)
|
||||
Returns
|
||||
-------
|
||||
gt_scaled, x_scaled
|
||||
"""
|
||||
if normalize_gt:
|
||||
gt = normalize(gt, 0.1, 99.9, clip=False).astype(np.float32, copy = False)
|
||||
x = x.astype(np.float32, copy=False) - np.mean(x)
|
||||
gt = gt.astype(np.float32, copy=False) - np.mean(gt)
|
||||
scale = np.cov(x.flatten(), gt.flatten())[0, 1] / np.var(x.flatten())
|
||||
return gt, scale * x
|
||||
|
||||
|
||||
def get_scores(gt, x, multichan=False):
|
||||
|
||||
gt_, x_ = norm_minmse(gt, x)
|
||||
|
||||
mse = compare_mse(gt_, x_)
|
||||
psnr = compare_psnr(gt_, x_, data_range = 1.)
|
||||
ssim = compare_ssim(gt_, x_, data_range = 1., multichannel=multichan)
|
||||
|
||||
return np.sqrt(mse), psnr, ssim
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
# ground truth image
|
||||
y = ascent().astype(np.float32)
|
||||
# input image to compare to
|
||||
x1 = y + 30*np.random.normal(0,1,y.shape)
|
||||
# a scaled and shifted version of x1
|
||||
x2 = 2*x1+100
|
||||
|
||||
# calulate mse, psnr, and ssim of the normalized/scaled images
|
||||
mse1 = compare_mse(*norm_minmse(y, x1))
|
||||
mse2 = compare_mse(*norm_minmse(y, x2))
|
||||
# should be the same
|
||||
print("MSE1 = %.6f\nMSE2 = %.6f"%(mse1, mse2))
|
||||
|
||||
psnr1 = compare_psnr(*norm_minmse(y, x1), data_range = 1.)
|
||||
psnr2 = compare_psnr(*norm_minmse(y, x2), data_range = 1.)
|
||||
# should be the same
|
||||
print("PSNR1 = %.6f\nPSNR2 = %.6f"%(psnr1,psnr2))
|
||||
|
||||
ssim1 = compare_ssim(*norm_minmse(y, x1), data_range = 1.)
|
||||
ssim2 = compare_ssim(*norm_minmse(y, x2), data_range = 1.)
|
||||
# should be the same
|
||||
print("SSIM1 = %.6f\nSSIM2 = %.6f"%(ssim1,ssim2))
|
||||
|
|
@ -0,0 +1,152 @@
|
|||
from __future__ import print_function, unicode_literals, absolute_import, division
|
||||
from six.moves import range, zip, map, reduce, filter
|
||||
|
||||
import collections
|
||||
import warnings
|
||||
import numpy as np
|
||||
|
||||
|
||||
def get_coord(shape, size, margin):
|
||||
n_tiles_i = int(np.ceil((shape[2]-size)/float(size-2*margin)))
|
||||
n_tiles_j = int(np.ceil((shape[1]-size)/float(size-2*margin)))
|
||||
for i in range(n_tiles_i+1):
|
||||
src_start_i = i*(size-2*margin) if i<n_tiles_i else (shape[2]-size)
|
||||
src_end_i = src_start_i+size
|
||||
left_i = margin if i>0 else 0
|
||||
right_i = margin if i<n_tiles_i else 0
|
||||
for j in range(n_tiles_j+1):
|
||||
src_start_j = j*(size-2*margin) if j<n_tiles_j else (shape[1]-size)
|
||||
src_end_j = src_start_j+size
|
||||
left_j = margin if j>0 else 0
|
||||
right_j = margin if j<n_tiles_j else 0
|
||||
src_s = (slice(None, None),
|
||||
slice(src_start_j, src_end_j),
|
||||
slice(src_start_i, src_end_i))
|
||||
|
||||
trg_s = (slice(None, None),
|
||||
slice(src_start_j+left_j, src_end_j-right_j),
|
||||
slice(src_start_i+left_i, src_end_i-right_i))
|
||||
|
||||
mrg_s = (slice(None, None),
|
||||
slice(left_j, -right_j if right_j else None),
|
||||
slice(left_i, -right_i if right_i else None))
|
||||
|
||||
yield src_s, trg_s, mrg_s
|
||||
|
||||
|
||||
# Below implementation of prediction utils inherited from CARE: https://github.com/CSBDeep/CSBDeep
|
||||
# Content-Aware Image Restoration: Pushing the Limits of Fluorescence Microscopy. Martin Weigert, Uwe Schmidt, Tobias Boothe, Andreas Müller, Alexandr Dibrov, Akanksha Jain, Benjamin Wilhelm, Deborah Schmidt, Coleman Broaddus, Siân Culley, Mauricio Rocha-Martins, Fabián Segovia-Miranda, Caren Norden, Ricardo Henriques, Marino Zerial, Michele Solimena, Jochen Rink, Pavel Tomancak, Loic Royer, Florian Jug, and Eugene W. Myers. Nature Methods 15.12 (2018): 1090–1097.
|
||||
|
||||
def _raise(e):
|
||||
raise e
|
||||
|
||||
def consume(iterator):
|
||||
collections.deque(iterator, maxlen=0)
|
||||
|
||||
def axes_check_and_normalize(axes,length=None,disallowed=None,return_allowed=False):
|
||||
"""
|
||||
S(ample), T(ime), C(hannel), Z, Y, X
|
||||
"""
|
||||
allowed = 'STCZYX'
|
||||
axes is not None or _raise(ValueError('axis cannot be None.'))
|
||||
axes = str(axes).upper()
|
||||
consume(a in allowed or _raise(ValueError("invalid axis '%s', must be one of %s."%(a,list(allowed)))) for a in axes)
|
||||
disallowed is None or consume(a not in disallowed or _raise(ValueError("disallowed axis '%s'."%a)) for a in axes)
|
||||
consume(axes.count(a)==1 or _raise(ValueError("axis '%s' occurs more than once."%a)) for a in axes)
|
||||
length is None or len(axes)==length or _raise(ValueError('axes (%s) must be of length %d.' % (axes,length)))
|
||||
return (axes,allowed) if return_allowed else axes
|
||||
|
||||
|
||||
def axes_dict(axes):
|
||||
"""
|
||||
from axes string to dict
|
||||
"""
|
||||
axes, allowed = axes_check_and_normalize(axes,return_allowed=True)
|
||||
return { a: None if axes.find(a) == -1 else axes.find(a) for a in allowed }
|
||||
|
||||
|
||||
def normalize_mi_ma(x, mi, ma, clip=False, eps=1e-20, dtype=np.float32):
|
||||
if dtype is not None:
|
||||
x = x.astype(dtype,copy=False)
|
||||
mi = dtype(mi) if np.isscalar(mi) else mi.astype(dtype,copy=False)
|
||||
ma = dtype(ma) if np.isscalar(ma) else ma.astype(dtype,copy=False)
|
||||
eps = dtype(eps)
|
||||
try:
|
||||
import numexpr
|
||||
x = numexpr.evaluate("(x - mi) / ( ma - mi + eps )")
|
||||
except ImportError:
|
||||
x = (x - mi) / ( ma - mi + eps )
|
||||
if clip:
|
||||
x = np.clip(x,0,1)
|
||||
return x
|
||||
|
||||
class PercentileNormalizer(object):
|
||||
|
||||
def __init__(self, pmin=2, pmax=99.8, do_after=True, dtype=np.float32, **kwargs):
|
||||
|
||||
(np.isscalar(pmin) and np.isscalar(pmax) and 0 <= pmin < pmax <= 100) or _raise(ValueError())
|
||||
self.pmin = pmin
|
||||
self.pmax = pmax
|
||||
self._do_after = do_after
|
||||
self.dtype = dtype
|
||||
self.kwargs = kwargs
|
||||
|
||||
def before(self, img, axes):
|
||||
|
||||
len(axes) == img.ndim or _raise(ValueError())
|
||||
channel = axes_dict(axes)['C']
|
||||
axes = None if channel is None else tuple((d for d in range(img.ndim) if d != channel))
|
||||
self.mi = np.percentile(img,self.pmin,axis=axes,keepdims=True).astype(self.dtype,copy=False)
|
||||
self.ma = np.percentile(img,self.pmax,axis=axes,keepdims=True).astype(self.dtype,copy=False)
|
||||
return normalize_mi_ma(img, self.mi, self.ma, dtype=self.dtype, **self.kwargs)
|
||||
|
||||
def after(self, img):
|
||||
|
||||
self.do_after or _raise(ValueError())
|
||||
alpha = self.ma - self.mi
|
||||
beta = self.mi
|
||||
return ( alpha*img+beta ).astype(self.dtype,copy=False)
|
||||
|
||||
def do_after(self):
|
||||
|
||||
return self._do_after
|
||||
|
||||
|
||||
class PadAndCropResizer(object):
|
||||
|
||||
def __init__(self, mode='reflect', **kwargs):
|
||||
|
||||
self.mode = mode
|
||||
self.kwargs = kwargs
|
||||
|
||||
def _normalize_exclude(self, exclude, n_dim):
|
||||
"""Return normalized list of excluded axes."""
|
||||
if exclude is None:
|
||||
return []
|
||||
exclude_list = [exclude] if np.isscalar(exclude) else list(exclude)
|
||||
exclude_list = [d%n_dim for d in exclude_list]
|
||||
len(exclude_list) == len(np.unique(exclude_list)) or _raise(ValueError())
|
||||
all(( isinstance(d,int) and 0<=d<n_dim for d in exclude_list )) or _raise(ValueError())
|
||||
return exclude_list
|
||||
|
||||
def before(self, x, div_n, exclude):
|
||||
|
||||
def _split(v):
|
||||
a = v // 2
|
||||
return a, v-a
|
||||
exclude = self._normalize_exclude(exclude, x.ndim)
|
||||
self.pad = [_split((div_n-s%div_n)%div_n) if (i not in exclude) else (0,0) for i,s in enumerate(x.shape)]
|
||||
x_pad = np.pad(x, self.pad, mode=self.mode, **self.kwargs)
|
||||
for i in exclude:
|
||||
del self.pad[i]
|
||||
return x_pad
|
||||
|
||||
def after(self, x, exclude):
|
||||
|
||||
pads = self.pad[:len(x.shape)]
|
||||
crop = [slice(p[0], -p[1] if p[1]>0 else None) for p in self.pad]
|
||||
for i in self._normalize_exclude(exclude, x.ndim):
|
||||
crop.insert(i,slice(None))
|
||||
len(crop) == x.ndim or _raise(ValueError())
|
||||
return x[tuple(crop)]
|
||||
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
|
||||
|
||||
def augment_patch(patch):
|
||||
if len(patch.shape[:-1]) == 2:
|
||||
patch = np.rot90(patch, k=np.random.randint(4), axes=(0, 1))
|
||||
elif len(patch.shape[:-1]) == 3:
|
||||
patch = np.rot90(patch, k=np.random.randint(4), axes=(1, 2))
|
||||
|
||||
patch = np.flip(patch, axis=-2) if np.random.randint(2) else patch
|
||||
return patch
|
||||
|
||||
|
||||
# Below implementation of stratified sampling inherited from Noise2Void: https://github.com/juglab/n2v
|
||||
# Noise2void: learning denoising from single noisy images. Krull, Alexander, Tim-Oliver Buchholz, and Florian Jug. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
|
||||
|
||||
def get_stratified_coords2D(coord_gen, box_size, shape):
|
||||
box_count_y = int(np.ceil(shape[0] / box_size))
|
||||
box_count_x = int(np.ceil(shape[1] / box_size))
|
||||
x_coords = []
|
||||
y_coords = []
|
||||
for i in range(box_count_y):
|
||||
for j in range(box_count_x):
|
||||
y, x = next(coord_gen)
|
||||
y = int(i * box_size + y)
|
||||
x = int(j * box_size + x)
|
||||
if (y < shape[0] and x < shape[1]):
|
||||
y_coords.append(y)
|
||||
x_coords.append(x)
|
||||
return (y_coords, x_coords)
|
||||
|
||||
|
||||
def get_stratified_coords3D(coord_gen, box_size, shape):
|
||||
box_count_z = int(np.ceil(shape[0] / box_size))
|
||||
box_count_y = int(np.ceil(shape[1] / box_size))
|
||||
box_count_x = int(np.ceil(shape[2] / box_size))
|
||||
x_coords = []
|
||||
y_coords = []
|
||||
z_coords = []
|
||||
for i in range(box_count_z):
|
||||
for j in range(box_count_y):
|
||||
for k in range(box_count_x):
|
||||
z, y, x = next(coord_gen)
|
||||
z = int(i * box_size + z)
|
||||
y = int(j * box_size + y)
|
||||
x = int(k * box_size + x)
|
||||
if (z < shape[0] and y < shape[1] and x < shape[2]):
|
||||
z_coords.append(z)
|
||||
y_coords.append(y)
|
||||
x_coords.append(x)
|
||||
return (z_coords, y_coords, x_coords)
|
||||
|
||||
def rand_float_coords2D(boxsize):
|
||||
while True:
|
||||
yield (np.random.rand() * boxsize, np.random.rand() * boxsize)
|
||||
|
||||
def rand_float_coords3D(boxsize):
|
||||
while True:
|
||||
yield (np.random.rand() * boxsize, np.random.rand() * boxsize, np.random.rand() * boxsize)
|
||||
Loading…
Reference in New Issue